Blog
Technical deep-dives on AI, machine learning, and software engineering.
Technical deep-dives on AI, machine learning, and software engineering.
Sandboxes are immensely useful in the AI era, especially for iterating on untrusted AI-generated code. While sandbox boot times are at present usually not the key latency bottleneck for autonomous agents, I often think about a world where agents branch rapidly in sandboxes for parallel exploration of solution spaces, where compute infra, not LLM inference, is the limiting factor for latency.
Inspired by the ComputeSDK sandbox benchmarks1. ComputeSDK maintains a benchmark of various cloud sandbox providers' boot times. More details here. and wanting to understand systems I use daily, I went down the rabbit hole of optimizing latencies for a Firecracker sandbox orchestrator.
The first version of this system was working in the most literal sense. You could create a sandbox, run a command, and destroy it. On paper, that is success. In practice, it took 2.725 seconds p95 to go from POST /create to the first successful POST /exec, and that is slow enough to break flow in any interactive product.
By the end of this iteration cycle, the same metric landed at 59.030ms p95. This write-up is for software engineers curious about VM internals (including me), not kernel specialists.
I did not preserve every early raw log, so this post reconstructs the journey from benchmark outputs, code changes, and progress notes. The goal is to show validated turning points, and not pretend that every micro-step was documented perfectly.
Throughout this post, TTI means:
TTI = /create (booting up a sandbox to a "ready" state) + first /exec (executing a simple echo command).
Here, ready means the guest responds to ping and guest network configuration has completed such that the sandbox can make outbound requests. Sandbox tear-downs are excluded from the measurements.
All numbers in this post were collected on one development laptop (ThinkPad T14 Gen 4):
6.18.13-200.fc43.x86_64)12 logical CPUs)30GiB RAMv1.13.1btrfs (/home/...)/tmp: mounted as tmpfs on this machine, which matters for reflink behaviorNote: one deliberate scope choice I made is that this journey excludes warm VM pools. I wanted the benchmark to answer a narrower question: how much of the boot/bring-up path can be optimized when every request starts from a cold create. That keeps each improvement attributable to control plane and microVM boot work, instead of pool hit-rate behavior.2. In production, warm pools still make sense for burst absorption and tail latency, but a faster cold path means you can operate with a smaller pool and recover faster when demand outpaces pre-warmed capacity.
MicroVMs are often described as "between containers and VMs". For this project, the useful framing was boot path and device model.
Containers are fast partly because they share the host kernel. Traditional VMs isolate more strongly but often pay for broad virtual hardware emulation and long boot paths. Firecracker's microVM model narrows the machine surface intentionally: minimal devices, clear API, strong isolation boundary.
Firecracker gives you a strong foundation, but your control plane architecture determines whether that potential turns into low latency.
At the API layer, the control plane is tiny:
POST /createPOST /execPOST /destroyUnderneath, /create is a pipeline:
Once Firecracker itself is reasonably configured, most latency comes from surrounding orchestration - cold-boot frequency, readiness modeling, repeated host setup per request, and accidental serialization in the control path.
Early on, many symptoms looked like latency bugs but were actually boot correctness bugs. That made benchmark results noisy and hard to trust.
Kernel/rootfs were the first place this surfaced.3. Kernel = guest OS core that boots first and handles CPU/memory/devices. Rootfs = guest disk image containing user-space binaries, init scripts, and services. You need both: kernel to boot and talk to virtio devices, rootfs to actually run processes.
I could not optimize latency on top of an unstable guest substrate, because every regression looked like "network slowness" when it was really boot setup drift.
For reference, the build entry points are:
guest/build-kernel.shguest/build-rootfs.shFirecracker expects a kernel that boots cleanly in a minimal virtio-centric environment. If key options are wrong, symptoms look chaotic: rootfs mount failures, virtio probe failures, guest services never coming up, and control-plane timeouts that look network-related but are actually boot-related.
In my runs, failures like root mount panic and virtio probe errors were the signal that boot-critical paths were not deterministic yet.
Concretely, guest/build-kernel.sh starts from Firecracker's own microVM CI config (microvm-kernel-ci-x86_64-6.1.config) and then applies explicit overrides before building vmlinux. Starting from Firecracker's config gave a known-good baseline; the overrides acted as guardrails to avoid host-to-host drift.
The main overrides do three things:
CONFIG_VIRTIO_BLK, CONFIG_VIRTIO_NET, CONFIG_VIRTIO_MMIO, CONFIG_EXT4_FS, CONFIG_DEVTMPFS[_MOUNT]) so the guest can mount rootfs and configure networking without relying on optional runtime module loading.CONFIG_MODULES=n, CONFIG_BLK_DEV_INITRD=n, CONFIG_ACPI=n).CONFIG_DEBUG_KERNEL=n, CONFIG_KALLSYMS=n, CONFIG_WERROR=n) so build/runtime behavior is more predictable for repeatable benchmark runs.In short, Firecracker's config was the compatibility baseline, and the overrides were workload-specific guardrails for deterministic boot and readiness.
So the kernel work here was essentially enforcing boot-critical invariants:
Once that stabilized, boot behavior became boring and predictable. Only then did benchmark numbers become trustworthy.
I moved to a deterministic rootfs assembly model based on staged minirootfs extraction and ext4 image construction. The practical reason was consistency across hosts and fewer container-runtime-specific surprises during image creation.
In guest/build-rootfs.sh, this is implemented as: construct the filesystem tree in a staging directory, install/enable required services there (notably sshd and a guest control agent introduced later), then materialize a sealed ext4 image with mkfs.ext4 -d. Two details mattered. Firstly, a build failure led me to ensure that pseudo-filesystems (/proc, /sys, /dev) are unmounted before mkfs -d, so runtime pseudo state is not accidentally captured during image population.4. mkfs.ext4 -d expects a stable directory tree. Pseudo-filesystems are live kernel views, not static files, so leaving them mounted can cause nondeterministic image-population failures (for example entries under /proc changing while being read). Secondly, the artifact is intentionally slimmed (resize2fs -M, plus cache/docs/manpage cleanup), which reduces IO and helps clone/restore latency in the hot path.
Beyond fixing that concrete build issue, there was a broader performance reason: unstable artifacts introduce noise. If base image setup is non-deterministic, every latency chart is suspect.
Putting kernel and rootfs together, sandbox readiness depends on this chain:
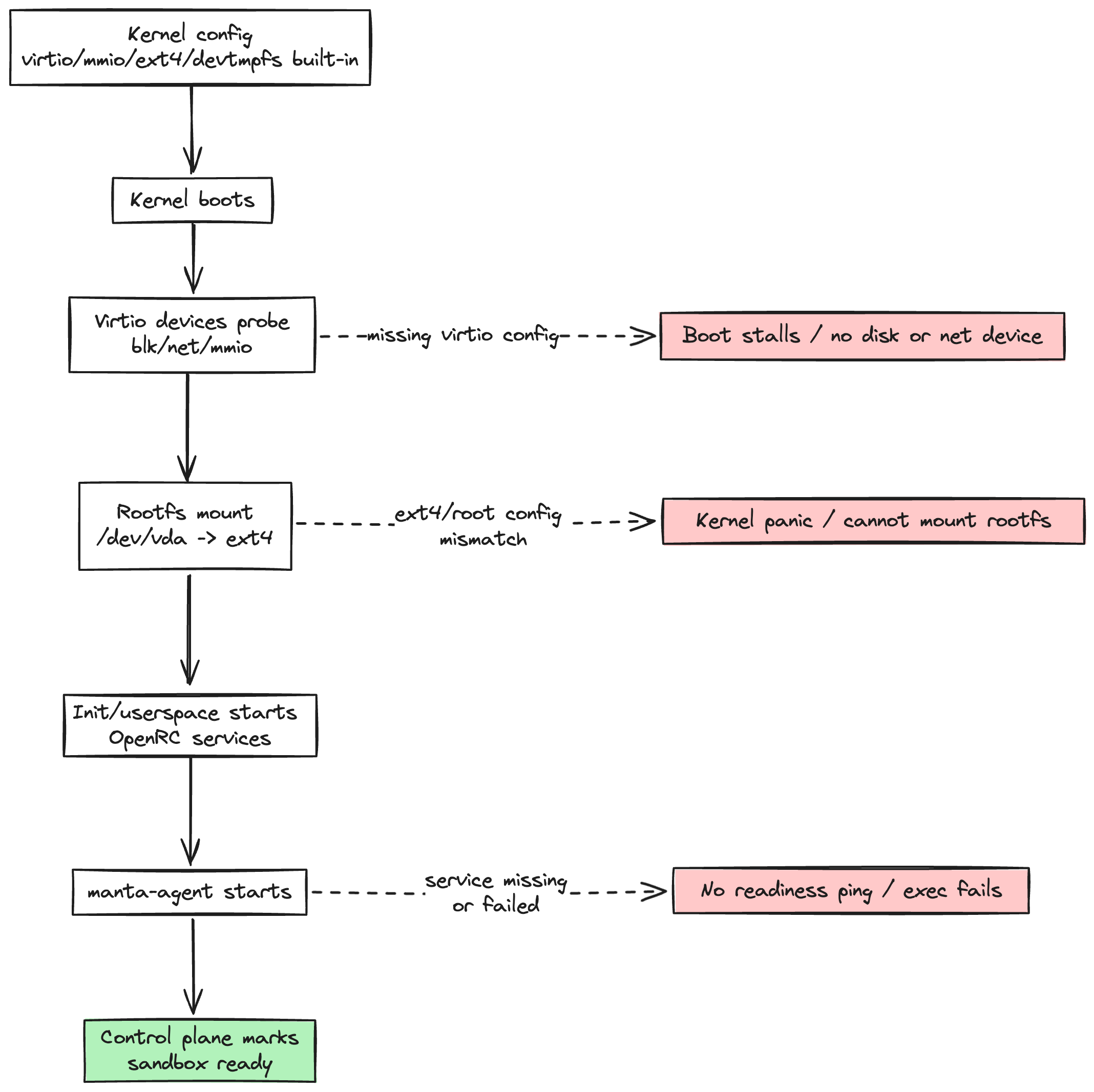
The first complete version used a conventional flow: cold boot microVM from kernel + rootfs, wait for SSH to become ready, execute the first command over SSH. This is simple, but also has all the cost centers in the request path.


One implementation detail that matters throughout this post is rootfs materialization. I use filesystem reflink cloning (cp --reflink=auto) so per-sandbox rootfs copies are copy-on-write on supporting filesystems; otherwise it can silently fall back to full copies.5. Reflink is a filesystem-level copy-on-write clone: a new "copy" initially shares data blocks and only diverges on write. It makes rootfs duplication much faster on supporting filesystems (for example btrfs).
The rough shape of the baseline looked like this:
func createAndExecNaive(req ExecRequest) ExecResult {
sb := allocateSandboxID()
rootfs := cloneRootfs(baseRootfs, sb.ID) // cp --reflink=auto
net := setupNetwork(sb.ID) // tap + routes + per-sandbox NAT churn
vm := firecrackerStart(kernelPath, rootfs, net)
waitUntilSSHReady(vm.GuestIP)
out := sshExec(vm.GuestIP, req.Command)
return out
}From 50 samples:
| min | p50 | p95 | p99 | max |
|---|---|---|---|---|
| 1.685s | 2.343s | 2.725s | 2.742s | 2.757s |
At this stage, optimization targets were obvious in principle but not in ordering. Should I optimize SSH first? Boot first? Host networking first? The next iterations answered that empirically.
The first major reduction came from changing the control channel.
I introduced an in-guest agent and moved readiness and exec to a vsock RPC path.6. vsock is a host guest communication channel exposed by the hypervisor, so control traffic does not need to traverse the full guest network stack in the same way as SSH-over-TCP. SSH remained in place as a reliability/debug fallback; only the latency-critical control path moved to vsock.
This shift matters because SSH, while robust, is a lot of protocol and session machinery for "run one command immediately after create". For repeated create/exec workloads, that machinery becomes a measurable tax.
vsock was a better fit for host guest control in this context:
As a result, p95 dropped from 2.725s to 472.275ms (~5.8x).
This was the first structural win: path redesign, not micro-optimization.
In simplified form, the transition looked like:
func execAfterCreate(sb Sandbox, cmd string) ExecResult {
// Old path:
// waitUntilSSHReady(sb.IP)
// return sshExec(sb.IP, cmd)
// New fast path:
waitUntilAgentPingOK(sb.VSock)
return agentRPCExec(sb.VSock, cmd)
}After Stage 1, pure cold boot was still expensive. The next change was to stop paying that cost per request.
A golden snapshot here is a pre-initialized baseline VM state captured ahead of request time:
state.snap)mem.snap)The system boots and prepares this baseline once, snapshots it, and then restores from it on /create. In other words, initialization is shifted from request-time work to preparation-time work.
This is exactly the kind of trade you want for latency-sensitive control planes: move repeatable expensive work off the critical path.
Request-time create from the golden snapshot looked roughly like:
func createFromGoldenSnapshot(req CreateRequest) Sandbox {
sb := allocateSandboxID()
rootfs := cloneRootfs(snapshotBaseDisk, sb.ID) // reflink when available
ns := acquireNetNSSlot() // pooled first, on-demand fallback
vm := firecrackerStartInNetNS(ns, rootfs)
firecrackerLoadSnapshot(vm, stateSnapPath, memSnapPath)
waitUntilAgentPingOK(sb.VSock)
agentRPCConfigureNetwork(sb.VSock, sb.IPConfig)
return sb
}netns (Linux network namespaces) gives each sandbox an isolated network stack.7. Think of it as each sandbox getting its own virtual network world: interfaces, routes, and firewall view. In Stage 2, the main latency win came from snapshot restore; netns was the enabler that made restore setup operationally clean and composable per sandbox. With per-sandbox namespaces, stable local device names can be reused without collisions. This also set up Stage 3, where netns pooling and netlink provisioning reduced host networking overhead further.
Combining snapshot restore with netns-based sandbox networking moved p95 to 190.617ms (~2.5x faster than previous stage).
With cold boot mostly out of the path, host networking setup emerged as the primary cost center.
Three changes mattered:
Per-sandbox iptables churn removed: Instead of mutating NAT rules for each sandbox, install a broader startup rule and stop touching iptables on every create/destroy.
Shell ip calls replaced with netlink APIs: Process spawning in the hot path adds overhead and failure surface. Direct netlink calls from Go removed both.
Network namespace pooling: Pre-create netns slots so create can often acquire prepared network context instead of building one from scratch.8. This is not indefinitely scalable on one host with one-octet subnet encoding and per-sandbox route/device growth. The next step is likely an allocator-based IPAM plus host-level scheduling for horizontal scale.
The theme here was amortization: if a setup step is repeated and deterministic, pre-do it or make it native.
At the networking layer, this was the core control flow:
func acquireNetNS() NetNSSlot {
if slot, ok := pool.TryAcquire(shortWindow); ok {
return slot
}
return createNetNSOnDemand()
}
func setupHostNetwork(sb Sandbox) error {
// Startup path installs one broad MASQUERADE rule once.
// Per-create path programs link/tap/routes via netlink.
return netlinkProgram(sb.NetNS, sb.Veth, sb.Tap, sb.Routes)
}The p95 latency is now 105.149ms.
At this point there was no single giant bottleneck. Gains came from shaving serialization and cleaning tail behavior.
ip commands with direct netlink operations reduced guest network setup time and variance once updated snapshots were rebuilt with the new agent.By the time these landed and stabilized, measured p95 reached 59.030ms.
Now, the latency breakdown is as such:
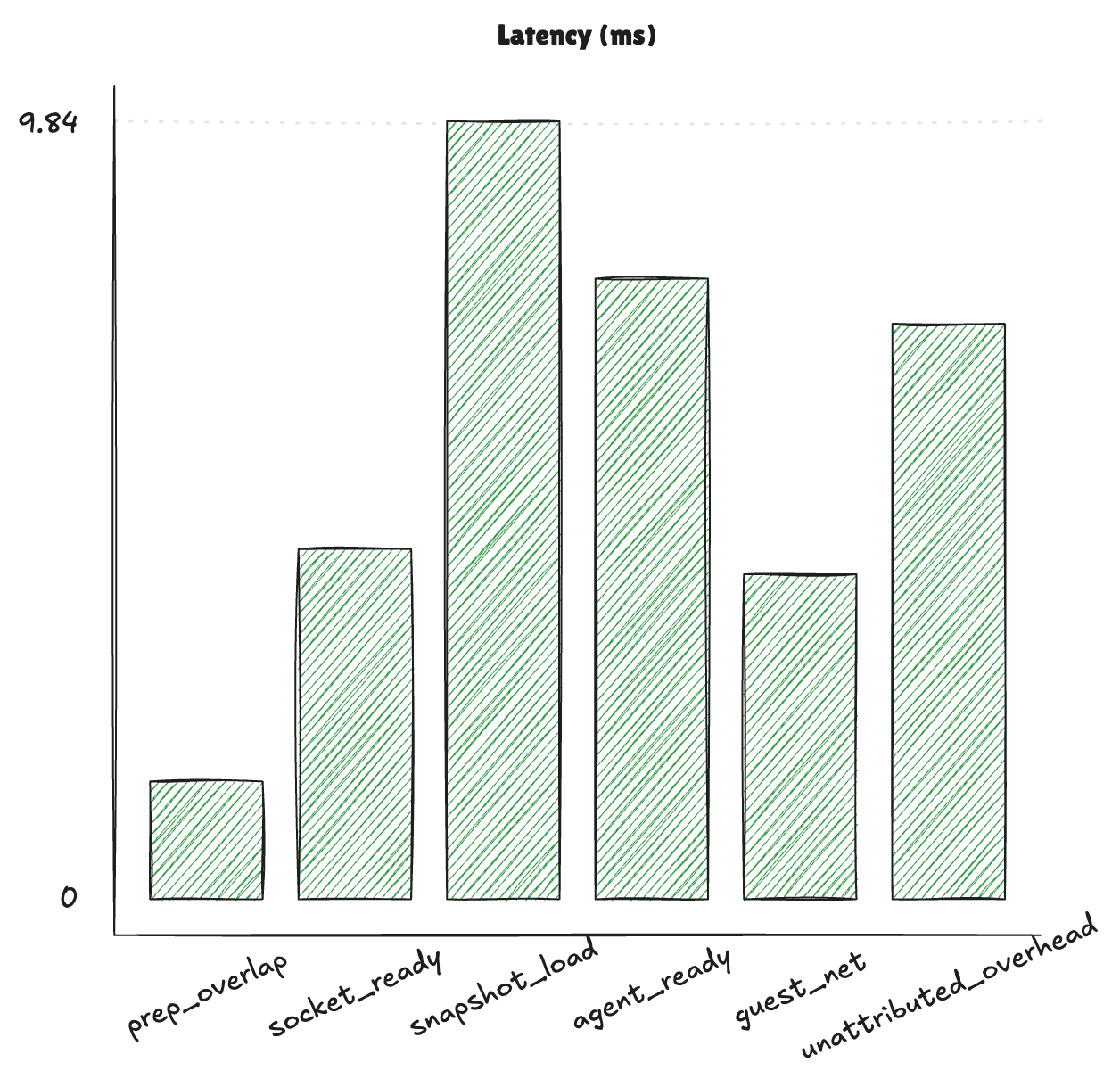
This chart uses one instrumented create sample and shows per-stage duration magnitudes for /create.
prep_overlap: wall-clock overlap window while disk materialization and netns acquisition run concurrently.socket_ready: time waiting for the Firecracker API Unix socket to become reachable after process start.snapshot_load: Firecracker /snapshot/load request time (state + memory restore).agent_ready: wait for post-restore in-guest agent handshake/ping readiness.guest_net: in-guest network configuration work (interface/address/route setup via agent).unattributed_overhead: remaining create-path time outside the explicit stage timers (bookkeeping, request/response plumbing, and small timing boundary gaps).At this point, the create path is broadly balanced: no single stage significantly dominates end-to-end latency. The largest remaining chunks are snapshot restore (snapshot_load), post-restore handshake (agent_ready), and residual orchestration cost (unattributed_overhead), so remaining improvements are likely very incremental unless a new architectural lever appears.
The optimized system looks like this:
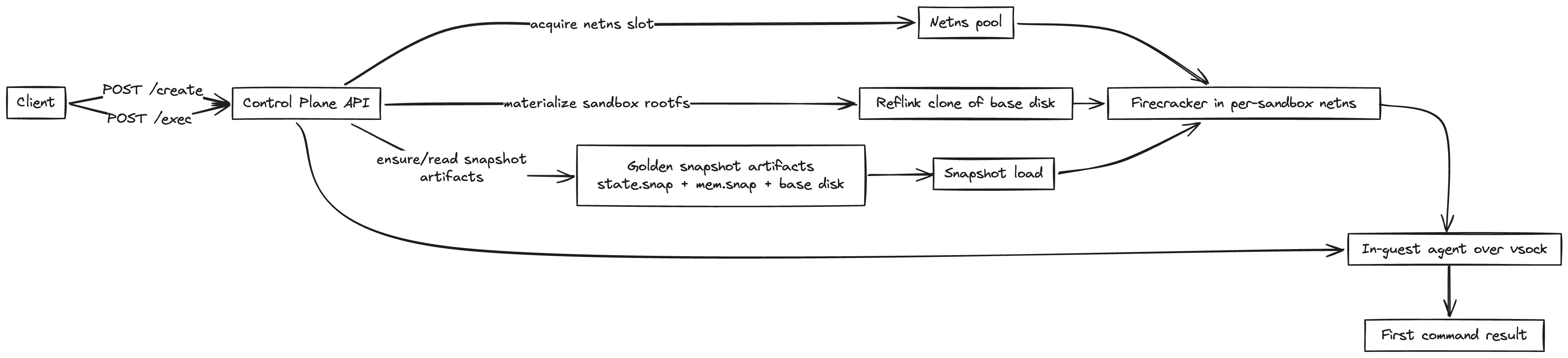
And here's a summary of the latency progression thus far:
| Stage | p95 TTI |
|---|---|
| Baseline cold-boot + SSH | 2725 ms |
| vsock RPC control path | 472 ms |
| Golden snapshot restore + netns | 191 ms |
| Netns pool + host netlink path | 105 ms |
| Parallelized setup + polling + guest netlink | 59 ms |
Overall, this is a ~46x p95 reduction!
Many symptoms looked like latency regressions, but root causes were ownership and sequencing errors. These bugs were major turning points in how I reasoned about the system.
--api-sock paths.ENOENT/ECONNREFUSED and long-tail retries.None of these are exotic, but all of them meaningfully affect tail latency and reliability. In practice, low-latency control planes are built on explicit contracts: process lifetime contract, readiness contract, and artifact path contract.
Some changes did not produce headline p95 drops:
auto vs strict reflink-required behavior)/tmp on this laptop (mounted as tmpfs) prevented the intended reflink fast path, so clone operations under --reflink=auto could fall back to real copies; moving MANTA_WORK_DIR to a btrfs-backed path restored copy-on-write clone behavior and improved create/restore consistency9. MANTA_WORK_DIR is the host-side directory where runtime artifacts are materialized (for example per-sandbox rootfs copies, snapshot files, and sandbox working directories), so its backing filesystem directly affects clone/restore behavior.These are still performance work in the long game. They prevent silent fallback cliffs and environment-specific regressions that would otherwise erase gains later.
The current design is intentionally pragmatic:
What comes next is less about shaving another few milliseconds and more about turning this into a production-grade system.
Follow my progress in this GitHub repo, and if there's anything that can be improved, I appreciate pointers and feedback.
This has been incredibly fun and I learned a lot, looking forward to taking this online next!